
[Work] 解決問題的過程
前言
「解決問題」可以說是工程師的日常,例如 需求下來了,準備實作功能時,如何去規劃?知道程式碼有 bug,要找出它並修好,使服務正常上線、服務 performance 不佳,想找出徵節點並加以改善等等。
雖然每天都在重複以上情境,卻沒留下什麼紀錄。我想藉由最近一次解決問題的經驗,來剖析自己面對問題時的思考、與後續採取動作的流程,做一次詳細的紀錄。
發現問題
最近在做一個以「計測週期」為條件撈取歷史資料,在前端利用線圖呈現的功能。計測週期從 每 10 秒、每小時、每天、到每月都有,而撈取資料的筆數固定為 16筆(往前推16個區間,包含當下),而資料組數則以「撈取多少個子節點」的資料決定。
使用 每 10 秒、每小時、每天 的計測週期撈取資料時,回應都在一秒以內。唯獨使用「月」的計測週期來撈取時,回應超過 7 秒。
情境補充
1. mainNode 與 subNode、meter 之間的關係
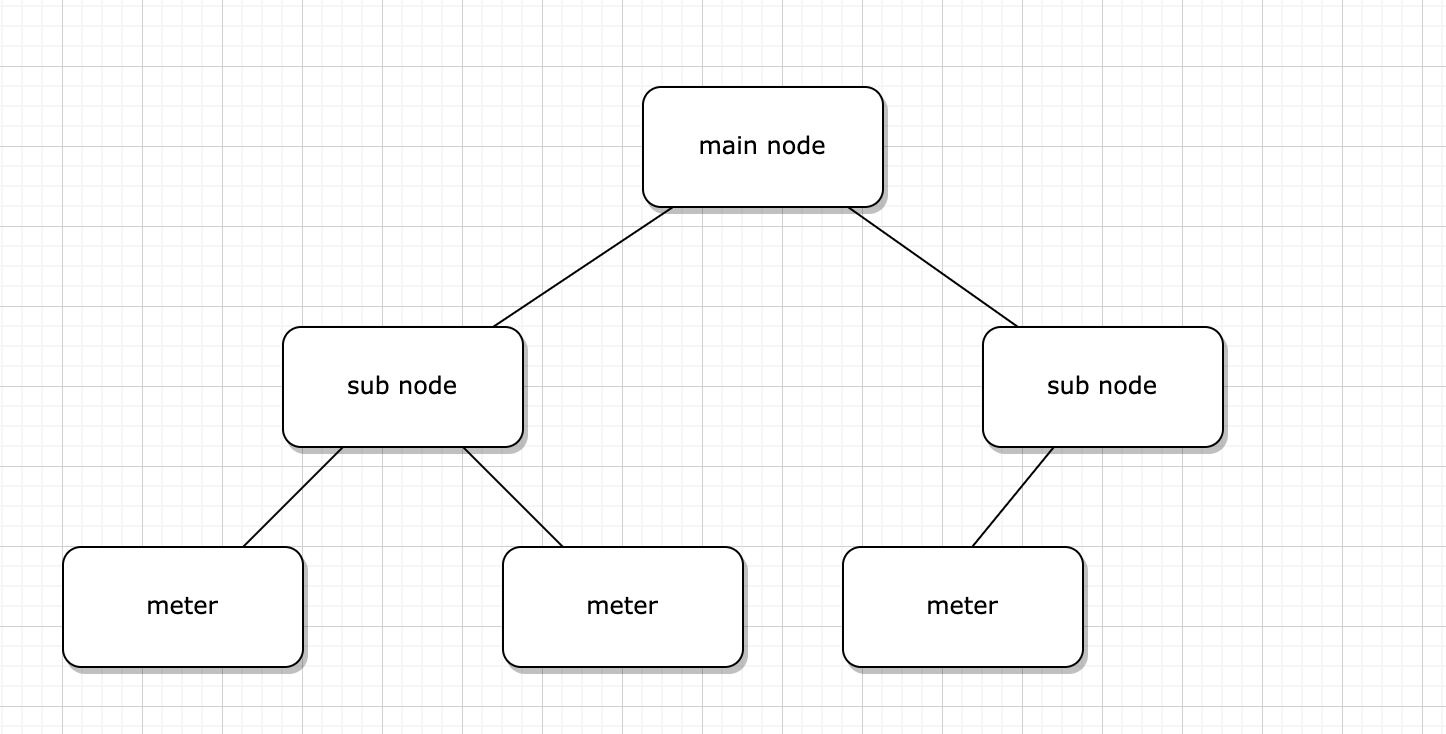
該功能為取得所有 subNode 下之 meter 資料加總,並以 subNode 分類呈現。而這次總共有 7 條產線(subNode),8 個 meter。
2. 不只撈取資料,也做 down sampling
由於連接 PLC 儲存資料的週期為每 10 秒一筆,因此 24 小時不間斷的儲存,每天都有 86400 筆。為了使撈取筆數和所需時間在不同計測週期時盡量不要差太多,故做了取樣。
3. 為了前端線圖函式庫所需,必須幫忙補 timestamp 與 null 值
由於有些機台會在某幾日或某些時段停機,這段時間內,PLC 並不會回傳資料,因此資料庫中的資料會有時間上的斷層。為了能夠讓前端繪製線圖,做了補 null 值與 timestamp 的動作。
4. 歷史包袱:每次都要打兩個 DB 撈取資料
目前資料庫由別的團隊管理,因資料量龐大,且容量有限,需搬移儲存或定期清理,當初設計時便決定將資料拆分為「今天」以及「今天以前」的資料,分別除存在兩個不同的 DB。若遇到撈取資料起始時間有跨今天及過去,會需要在兩個資料庫撈取資料並做合併。
收集資訊
發現問題之後,必須先收集能夠「證明這的確造成問題」、以及「問題到底發生在哪」的資訊。這次會發現問題主要是因為前端在串接資料時發現線圖畫的好慢,跟後端反映要求資料時間過長。
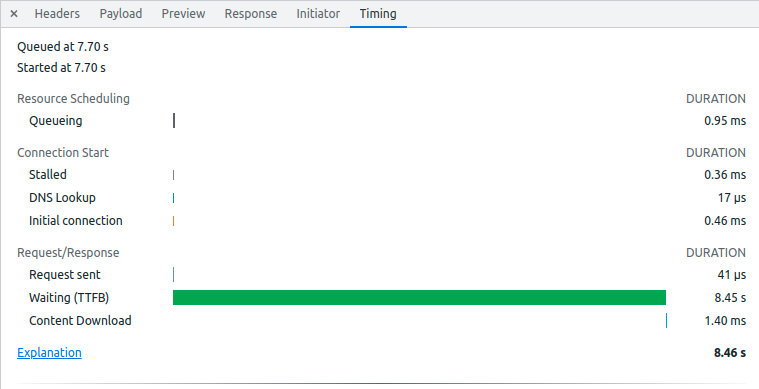
收到前端的 feedback 後,我便著手尋找問題出處。首先想再次確認究竟是前端還是後端的問題,我使用 devTools 查看瀏覽器 request 的 Timing,發現Waiting(TTFB) 超級久,看來是後端 API response 拖時間。
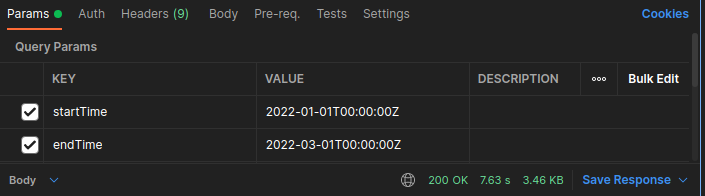
再來我使用 postman 測試這支 API,輸入一樣的參數,觀察 response time:
確定是後端問題後,回到這支 API 的 controller 檢視到底是哪個 function 拖最久時間:
之前整頓過架構,將 controller 中的 function 再拆開,依據職責封裝到 model 或 helper 中。目前已經包裝很精簡,函式粒度適中、一個函式只做一件事,所以可以快速測試花費時間。我在呼叫該 function 那行的前後,加上 console.log(new Date().getTime()),來看這個 function 花了多久才回傳值
pseudo code:
function getData(source) {
// 一些非同步程式碼
}
console.log(`START: ${new Date().getTime()}`)
const data = await getData('database1')
console.log(`END: ${new Date().getTime()}`)
到這邊發現是有去 DB 撈資料的 function 在拖,而且兩個 function 差不多時間。於是選了一個進去追,從 model 層(組裝/加總)到 helper 層(純撈),看到底是哪裡拖。
原來是 helper 層(純撈)在拖阿!
於是我印出 SQL logging,把 raw SQL 貼去 workbench 執行,觀察一下 performance:
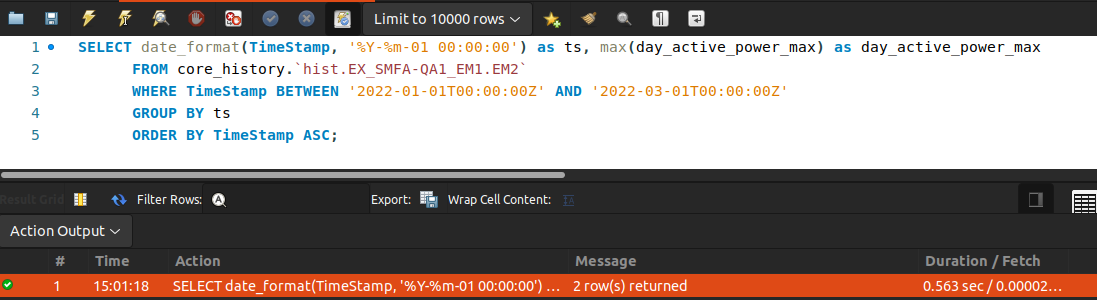
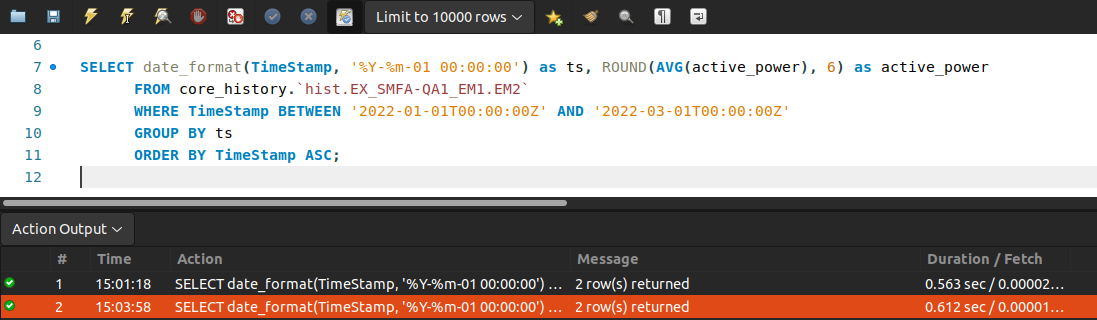
原來一條產線一次的 query 時間就是花這麼久。回頭看程式碼,有幾個產線迴圈就跑幾次,算算產線數、比對回應時間,這個結果是合理的,看來拖慢時間的部份是這裡。
分析原因、得出結論(問題點)
看了 SQL performance,Using where; Using temporary; Using filesort 可以理解它就是會花這麼多時間(temporary, filesort 都很耗時)
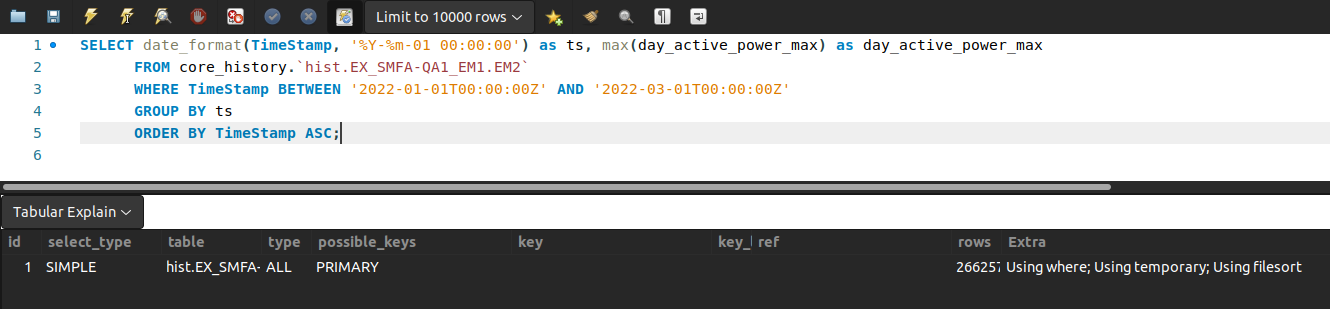
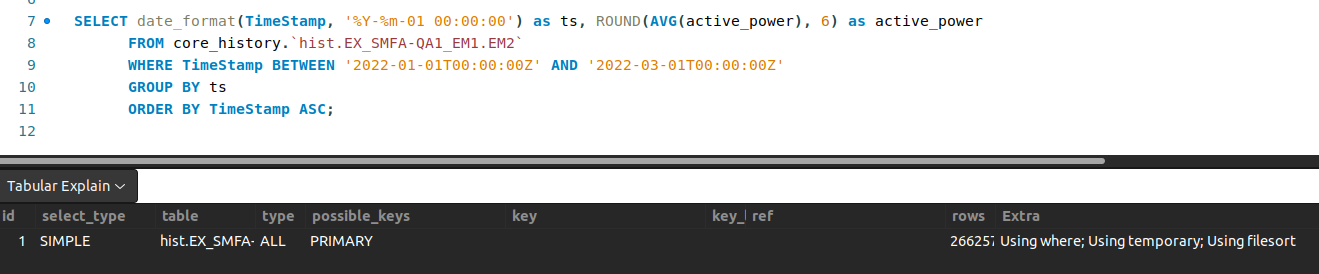
關於 filesort, temporary,我查到一些資料一、資料二,之後有空來研究看看。
定位問題點後得到結論:這些呼叫資料庫的非同步程式碼必須被優化。
討論可行方法
聚焦問題後,就是討論可行的解決方式。要優化呼叫資料庫的非同步程式碼,我想到了兩個方向:
1. 優化 raw query
一切的源頭就是這個 query 花太久時間。一個電錶是一次 query,而一次 query 是 500 毫秒。
- 如果能把它降到 500 毫秒以下,就算是累加多個電錶,也會低於原本的總毫秒數。
2. 使用 Promise.all():
因為目前都是用 await 寫成類同步程式碼,因此一個等一個,都在排隊,當然比較慢。
- 如果可以同時出發去做,時間就可以不用累加,而是縮短成一次所需的時間
- 例子說明:原本 500毫秒 * 7 條產線 = 3500 毫秒,使用 Promise.all() 讓所有 query 同時出發,照理來說至少不會是 3500 毫秒那麼久
評估現狀與決定 solution
限制
在決定做法之前,團隊有些既有的考量與限制:
- 根據之前計畫實作 down sampling 下的語法與日後維護上的需求,不能更動原本的 raw SQL
- 為了維持對資料庫操作的一致性,不管撈取資料的起迄時間為何,一律都打兩個資料庫取資料
綜合以上因素,既然不能對 query 做手腳,也不能減少打資料庫的次數,那只能使用 Promise.all() 來處理非同步的部份,試著優化等待時間。這麼一來只要對這些節點迴圈做包裝、甚至更內層的「同時查不同資料庫」做包裝,在程式碼的可讀性上還是能夠維持一致。
修正過程與實做結果測試
將原本使用 async/await 寫的程式碼用 Promise.all() 包裝 (pseudo code)
// helper 層 (從資料庫撈取 raw data)
async function getData() {
try {
const rawSQLToday = <raw SQL>
const rawSQLBeforeToday = <raw SQL>
const rawDataToday = new Promise((resolve, reject) => {
<當日 DB>.query(rawSQLToday, {
raw: true,
nest: true
}).then((data) => {
return resolve(data)
}).catch((error) => {
reject(error)
})
})
const rawDataBeforeToday = new Promise((resolve, reject) => {
<歷史 DB>.query(rawSQLBeforeToday, {
raw: true,
nest: true
}).then((data) => {
return resolve(data)
}).catch((error) => {
reject(error)
})
})
return Promise.all([rawDataBeforeToday, rawDataToday]).then((data) => {
return data
})
} catch (error) {
throw new Error(`historicalData_helper/getAvgTotalPerPeriod: ${error.stack}`)
}
}
// 電錶層 (撈出來依電錶分組)
async function getInstantPowerAvgPerPeriod() {
try {
const powerMeters = <取得電錶資料>
const promises = powerMeters.map((meter) => {
return new Promise((resolve, reject) => {
helper.getAvgTotalPerPeriod().then((data) => {
return resolve(data)
}).catch((error) => {
reject(error)
})
})
})
return Promise.all(promises).then((data) => {
return result
})
} catch (error) {
console.error(error)
throw error
}
}
// 節點層,依此類推
以節點為單位去打包,用 Promise.all() 同時去做節點內該做的事情
並同時結束(最後一個返回的節點 result 的時間,代表其他節點都完成了)
結果展示
只改一個 function 就比原本快了兩秒(共兩個 function):5.41 s
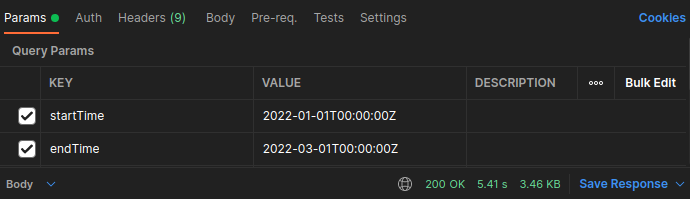
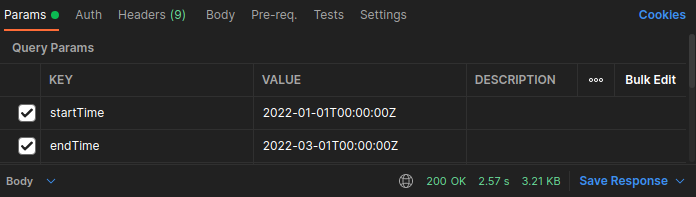
兩個都改完後,執行時間降到 2.57s
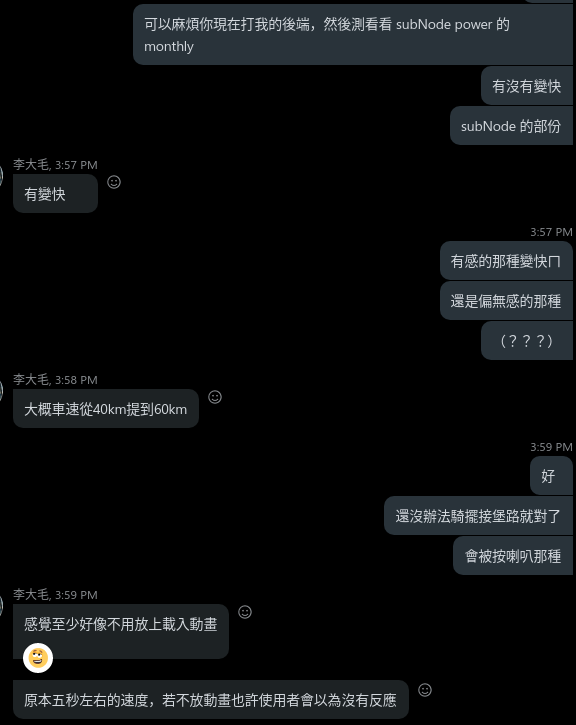
與前端對測後,前端工程師表示:
後記
這次的優化對我來說是一個不錯的經驗,雖然時程上比較趕,畢竟工作上有交期。學生時期顯少有機會對自己的程式碼進行一個全局的檢視、定位問題、並逐步安排優化。而這次不管是 debug 或是優化過程中都學到很多,分別是:
1. 拆解問題的過程
在這次拆解問題的過程,我先剖析這支 API 中有呼叫了哪些外部 function,因為除了呼叫外部 function 的部份外,我認為站在維護的角度,在 controller 層中的程式碼,時間複雜度上都必須盡可能降到最低(已經不能再對 raw data 做操作,頂多就是組成前端想要的格式),因此較重的 loading 應該會發生在撈資料的層級。
縮小範圍後,我只需要在呼叫外部 function 的前後印印看執行時間,就能夠大致定位問題出在哪個 function 裡。由於這次的功能模組有將資料流做詳細的分層,因此由外而內的定位問題變得容易許多。
找到問題點後需要分析背後的原因,這部份也讓我有機會去認識有哪些事情會拖慢效能,常見的例子是什麼、作法有哪些。這是學生時期再寫自己的小專案時,沒辦法體驗到的(規模太小),剛好工作上操作的資料量很大,是一次實際見習的好機會。
2. 尋找優化方案
在尋找優化方案的時候,因為本身經驗尚淺,雖有跡可循、但不確定有什麼好作法。透過跟技術主管的討論、以及過去工作經驗上的分享,也獲得許多實務上的經驗以及「遇到問題時的直覺」的傳承。在 stack overflow 上尋求答案時,也看到許多擁有多年開發經驗的工程師分享比較 general 的狀況,還有如何避免寫出造成效能問題的 code 等。
3. 重新認識 Promise
在這次重構之前,因習慣使用 async/await 寫出乾淨的非同步程式碼,較少有機會使用 Promise 或 promise-based 的語法。這次為了將程式碼包裝程 Promise.all() 的寫法,好好研究了一番,不管是 Promise.all()、Promise.race() 等等,把 JavaScript 基礎扎穩。
4. 重構心得
雖然這次是重構自己寫的東西(這包 owner 只有我),在初次開發功能時,也是很認真的想寫出乾淨簡潔的程式碼,但仍免不了重構的需要。這也讓我反思,縱使當初自認為設想的多周到,總是有需要改善、改進、或是打掉重練的地方。不管是需求改變或是效能調整,當初開發的東西其實是以 MVP 產品為目標,在有限的時間內開發出最基礎的功能,因此仍需不斷改進、增減內容,產品都會經歷這樣的迭代過程,很正常。
過去常常在開發時碰壁,因為自認寫了比較冗的 code,苦惱著為何沒辦法「一步到位」,做出「以後再也不需要回來重構的完美程式碼」,也常因為這樣糾結許久,雖不至於拖延到開發時程,但心裡總是有疙瘩。或許是害怕當初寫的雜亂,事後回來看時會花費許多時間理解當初的程式碼邏輯,但還好平常就在練習提昇易讀性、來回重構時也練習快速看懂程式碼架構與流程,能夠只聚焦在需要修正的地方,因此不只當初的焦慮消失,這同時也是很好的練習。
雖然現在的我還沒辦法做出多厲害的效能調校,成果也不是最棒,因為使用者的耐心有限。但看到 query 速度少了一倍心裡還是有一點成就感。希望能夠在這部份多多鑽研,深入學習資料庫、同步非同步機制、底層運作,以及磨練自己寫程式的能力,未來寫出乾淨易讀又有效率的程式碼。
更新
後來使用了 Redis 做 caching service 之後,整個 response time 加速許多,因為只要 Redis cache 裡有資料,就不需要再去 MariaDB 撈取了。就算只有部份 cache,需要去 MariaDB 撈的資料量也變少了,整體 response time 幾乎能縮短到半秒之內。在研究 Redis 的過程中也是收穫滿滿,現在又多了一項工具、一種優化方式可以使用。